
生成式任务
生成式任务可以分为 auto regressive 和 non auto regressive 两大类策略。
auto regressive: 模型一次forward只生成一个token(像素),然后把生成的token重新作为输入的一部分, 生成下一个token,直到生成 END token。auto regressive 模型的数学公式可以表示如下:
\[p(x)=\prod_{i=1}^n p\left(x_i \mid x_1, x_2, \ldots, x_{i-1}\right)= \prod_{i=1}^n p\left(x_i \mid x_{<i}\right)\]non auto regressive: 模型一次forward生成所有的token(像素); 对于文本未确定的长度,可以让模型输出固定的长度,END 作为结束token, 第一个END出现的地方就是句子结束的地方;也可以首先让模型forward一次,输出句子的长度,然后再生成对应长度的句子。
文本的生成一般都是采用auto regressive 的方法,因为文本本身的序列性, 以及序列的长度相对于图像一般短很多,采用 auto regressive 的方法是比较自然,同时计算量也是可以接受的。
图像生成一般是采用 non auto regressive 的方法,即一次性生成一整张图像。 这是因为图像的像素数量非常的多,将一张图像flatten 成一个序列,往往序列会非常长, auto regressive 的计算时间就会非常长。 实际上,使用 auto regressive 的方式生成图像是完全可以 (openai 就做过这个研究: https://openai.com/research/image-gpt)。
| 生成速度 | 生成质量 | 应用领域 | |
|---|---|---|---|
| auto regressive | 比较慢 | 比较好 | 常用于文字 |
| non auto regressive | 比较快 | 更多噪声/模糊 | 常用于图像 |
两种策略融合
- 使用 auto regresive 的方式生成一个低”分辨率“的中间结果,
然后再将中间结果输入 non auto regressive 的模型,生成最终的结果。
- 一般可以认为,auto regresive 的方式生成的低”分辨率“的中间结果,
控制了non auto regressive 模型的生成的大方向,
减少了non auto regressive模型生成过程中不够确定的因素。
以语音合成为例:
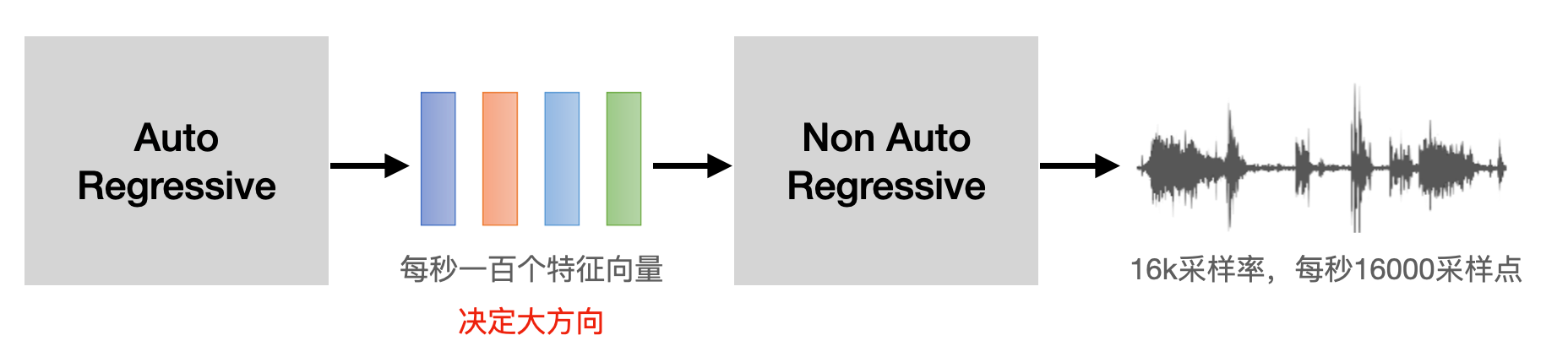
- 一般可以认为,auto regresive 的方式生成的低”分辨率“的中间结果,
控制了non auto regressive 模型的生成的大方向,
减少了non auto regressive模型生成过程中不够确定的因素。
以语音合成为例:
- non auto regressive 模型一次生成结果的方式,改成多次迭代生成结果。
- 虽然每次都是生成最终结果需要的token量(分辨率),但是由于多次迭代才是最终的结果,
前面一次的结果可以为后面一次生成提供一个大方向,减少其生成过程中不够确定的因素。
以图像生成为例:
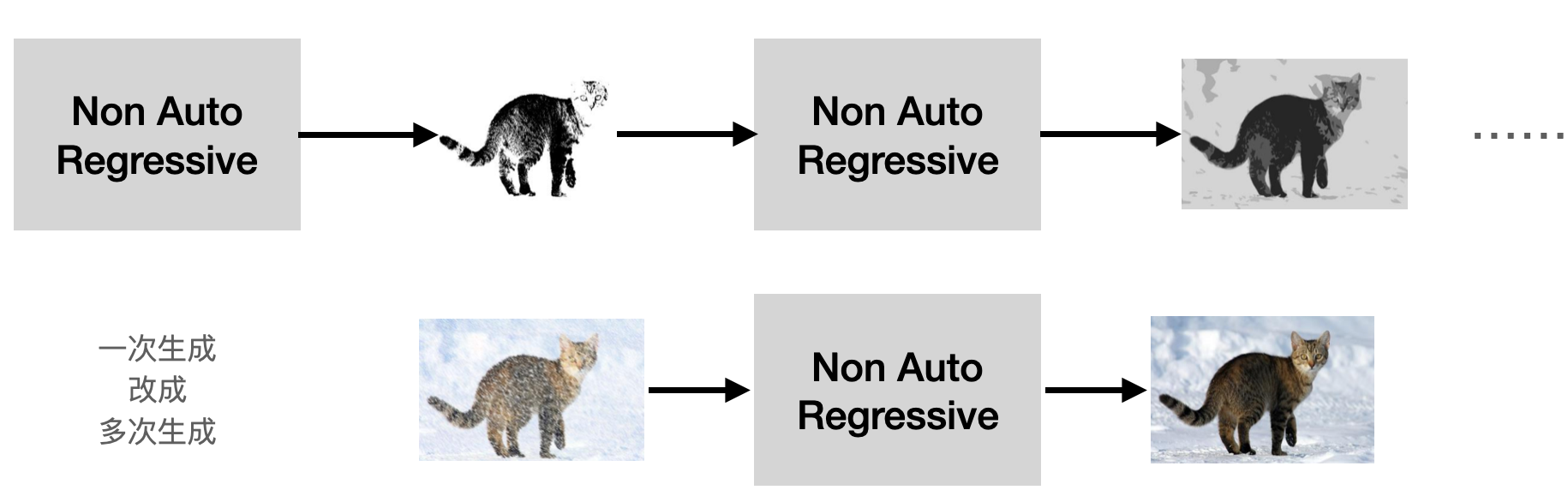
- 虽然每次都是生成最终结果需要的token量(分辨率),但是由于多次迭代才是最终的结果,
前面一次的结果可以为后面一次生成提供一个大方向,减少其生成过程中不够确定的因素。
以图像生成为例:
第二种融合的方式看起来就很像diffusion model 做的方式。
图像生成
图像生成任务可以简单的用以下示意图来表示

如图所示,图像生成任务是希望:输入一句话或者一张图片,生成符合描述的新的图片。
但是这个任务再只有一句话或者一张图片作为输入的情况下,是有问题的; 因为需要生成的结果往往是有很多种可以满足描述的结果。 即是说,在仅有依赖文字/图像的输入,这是一个“一对多”的问题。 实际上,我们可以理解为,在确定的文字/图像输入的情况下,可能生成的图像结果构成一个概率分布。
因此,在我们实现一个图像生成模型的时候,除了我们输入的文字/图像以外, 还会额外的从某个概率分布(一般是高斯分布)里采样一个特征作为输入
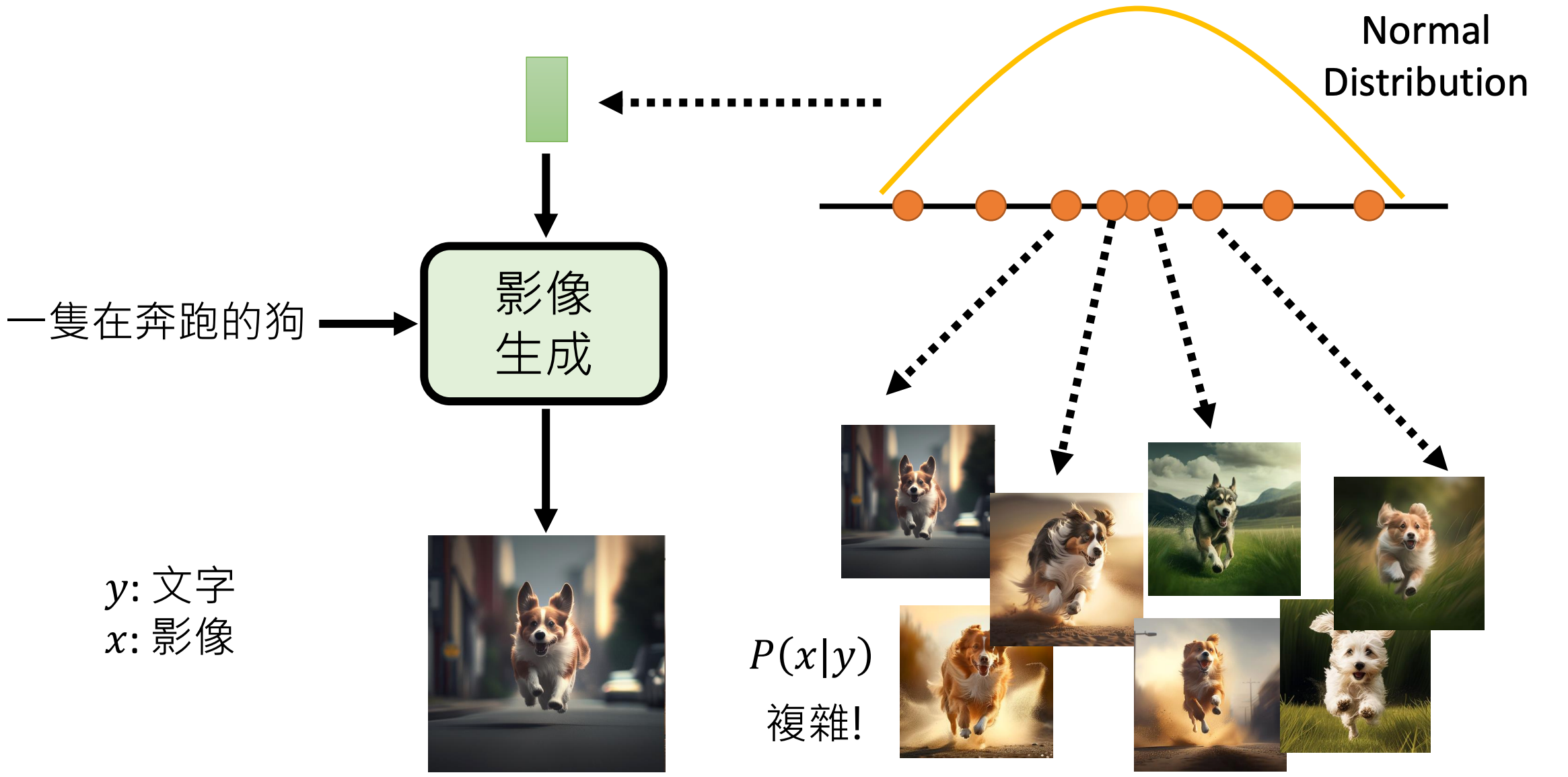
所以,图像生成模型需要做的实际上是,把高斯分布映射到生成结果所构成的概率分布; 而输入的文字/图像是对结果所构成的概率分布做了限制(需要满足输入的描述,而不是所有图像的概率空间)。
所以图像生成任务实际上是需要寻找某种方式把高斯分布映射到生成结果所构成的概率分布。
而寻找这样的映射方式,或者说映射函数就是各种图像生成模型在做的事情, 目前比较有名的图像生成模型有:VAE, diffusion model, flow-based generative model, GAN。




